Vowpal Wabbit and LightGBM for a Regression Problem
This notebook shows how to build simple regression models by using Vowpal Wabbit (VW) and LightGBM with SynapseML. We also compare the results with Spark MLlib Linear Regression.
import math
from synapse.ml.train import ComputeModelStatistics
from synapse.ml.vw import VowpalWabbitRegressor, VowpalWabbitFeaturizer
from synapse.ml.lightgbm import LightGBMRegressor
import numpy as np
import pandas as pd
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression
from sklearn.datasets import fetch_california_housing
Prepare Dataset
We use California Housing dataset.
The data was derived from the 1990 U.S. census. It consists of 20640 entries with 8 features.
We use sklearn.datasets module to download it easily, then split the set into training and testing by 75/25.
california = fetch_california_housing()
feature_cols = ["f" + str(i) for i in range(california.data.shape[1])]
header = ["target"] + feature_cols
df = spark.createDataFrame(
pd.DataFrame(
data=np.column_stack((california.target, california.data)), columns=header
)
).repartition(1)
print("Dataframe has {} rows".format(df.count()))
display(df.limit(10).toPandas())
train_data, test_data = df.randomSplit([0.75, 0.25], seed=42)
Following is the summary of the training set.
display(train_data.summary().toPandas())
Plot feature distributions over different target values (house prices in our case).
features = train_data.columns[1:]
values = train_data.drop("target").toPandas()
ncols = 5
nrows = math.ceil(len(features) / ncols)
Baseline - Spark MLlib Linear Regressor
First, we set a baseline performance by using Linear Regressor in Spark MLlib.
featurizer = VectorAssembler(inputCols=feature_cols, outputCol="features")
lr_train_data = featurizer.transform(train_data)["target", "features"]
lr_test_data = featurizer.transform(test_data)["target", "features"]
display(lr_train_data.limit(10))
# By default, `maxIter` is 100. Other params you may want to change include: `regParam`, `elasticNetParam`, etc.
lr = LinearRegression(labelCol="target")
lr_model = lr.fit(lr_train_data)
lr_predictions = lr_model.transform(lr_test_data)
display(lr_predictions.limit(10))
We evaluate the prediction result by using synapse.ml.train.ComputeModelStatistics which returns four metrics:
- MSE (Mean Squared Error)
- RMSE (Root Mean Squared Error) = sqrt(MSE)
- R Squared
- MAE (Mean Absolute Error)
metrics = ComputeModelStatistics(
evaluationMetric="regression", labelCol="target", scoresCol="prediction"
).transform(lr_predictions)
results = metrics.toPandas()
results.insert(0, "model", ["Spark MLlib - Linear Regression"])
display(results)
Vowpal Wabbit
Perform VW-style feature hashing. Many types (numbers, string, bool, map of string to (number, string)) are supported.
vw_featurizer = VowpalWabbitFeaturizer(inputCols=feature_cols, outputCol="features")
vw_train_data = vw_featurizer.transform(train_data)["target", "features"]
vw_test_data = vw_featurizer.transform(test_data)["target", "features"]
display(vw_train_data.limit(10))
See VW wiki for command line arguments.
# Use the same number of iterations as Spark MLlib's Linear Regression (=100)
args = "--holdout_off --loss_function quantile -l 0.004 -q :: --power_t 0.3"
vwr = VowpalWabbitRegressor(labelCol="target", passThroughArgs=args, numPasses=100)
# To reduce number of partitions (which will effect performance), use `vw_train_data.repartition(1)`
vw_train_data_2 = vw_train_data.repartition(1).cache()
print(vw_train_data_2.count())
vw_model = vwr.fit(vw_train_data_2.repartition(1))
vw_predictions = vw_model.transform(vw_test_data)
display(vw_predictions.limit(10))
metrics = ComputeModelStatistics(
evaluationMetric="regression", labelCol="target", scoresCol="prediction"
).transform(vw_predictions)
vw_result = metrics.toPandas()
vw_result.insert(0, "model", ["Vowpal Wabbit"])
results = pd.concat([results, vw_result], ignore_index=True)
display(results)
LightGBM
lgr = LightGBMRegressor(
objective="quantile",
alpha=0.2,
learningRate=0.3,
numLeaves=31,
labelCol="target",
numIterations=100,
)
repartitioned_data = lr_train_data.repartition(1).cache()
print(repartitioned_data.count())
lg_model = lgr.fit(repartitioned_data)
lg_predictions = lg_model.transform(lr_test_data)
display(lg_predictions.limit(10))
metrics = ComputeModelStatistics(
evaluationMetric="regression", labelCol="target", scoresCol="prediction"
).transform(lg_predictions)
lg_result = metrics.toPandas()
lg_result.insert(0, "model", ["LightGBM"])
results = pd.concat([results, lg_result], ignore_index=True)
display(results)
Following figure shows the actual-vs.-prediction graphs of the results:
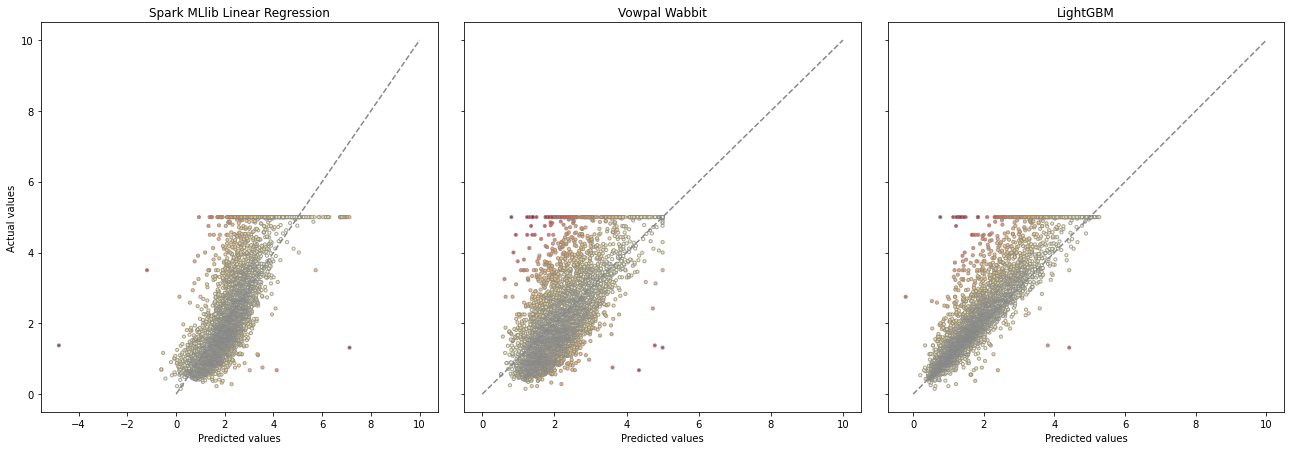
from matplotlib.colors import ListedColormap, Normalize
from matplotlib.cm import get_cmap
import matplotlib.pyplot as plt
f, axes = plt.subplots(nrows, ncols, sharey=True, figsize=(30, 10))
f.tight_layout()
yy = [r["target"] for r in train_data.select("target").collect()]
for irow in range(nrows):
axes[irow][0].set_ylabel("target")
for icol in range(ncols):
try:
feat = features[irow * ncols + icol]
xx = values[feat]
axes[irow][icol].scatter(xx, yy, s=10, alpha=0.25)
axes[irow][icol].set_xlabel(feat)
axes[irow][icol].get_yaxis().set_ticks([])
except IndexError:
f.delaxes(axes[irow][icol])
cmap = get_cmap("YlOrRd")
target = np.array(test_data.select("target").collect()).flatten()
model_preds = [
("Spark MLlib Linear Regression", lr_predictions),
("Vowpal Wabbit", vw_predictions),
("LightGBM", lg_predictions),
]
f, axes = plt.subplots(1, len(model_preds), sharey=True, figsize=(18, 6))
f.tight_layout()
for i, (model_name, preds) in enumerate(model_preds):
preds = np.array(preds.select("prediction").collect()).flatten()
err = np.absolute(preds - target)
norm = Normalize()
clrs = cmap(np.asarray(norm(err)))[:, :-1]
axes[i].scatter(preds, target, s=60, c=clrs, edgecolors="#888888", alpha=0.75)
axes[i].plot((0, 60), (0, 60), line, color="#888888")
axes[i].set_xlabel("Predicted values")
if i == 0:
axes[i].set_ylabel("Actual values")
axes[i].set_title(model_name)